看一遍就理解:order by 详解
日常开发中,我们经常会使用到order by,
亲爱的小伙伴,你是否知道order by 的工作原理呢?
order by的优化思路是怎样的呢?
使用order by有哪些注意的问题呢?
本文将跟大家一起来学习,攻克order by~
一个使用order by 的简单例子
假设用一张员工表,表结构如下:
// 创建表结构
CREATE TABLE `staff` (
`id` BIGINT ( 11 ) AUTO_INCREMENT COMMENT '主键id',
`id_card` VARCHAR ( 20 ) NOT NULL COMMENT '身份证号码',
`name` VARCHAR ( 64 ) NOT NULL COMMENT '姓名',
`age` INT ( 4 ) NOT NULL COMMENT '年龄',
`city` VARCHAR ( 64 ) NOT NULL COMMENT '城市',
PRIMARY KEY ( `id`),
INDEX idx_city ( `city` )
) ENGINE = INNODB COMMENT '员工表';
// 插入数据SQL语句
INSERT INTO `test`.`staff` (`id`, `id_card`, `name`, `age`, `city`) VALUES ('1', '', '小明', '22', '广州');
INSERT INTO `test`.`staff` (`id`, `id_card`, `name`, `age`, `city`) VALUES ('2', '', '小李', '23', '深圳');
INSERT INTO `test`.`staff` (`id`, `id_card`, `name`, `age`, `city`) VALUES ('3', '', '小刚', '28', '东皖');
INSERT INTO `test`.`staff` (`id`, `id_card`, `name`, `age`, `city`) VALUES ('4', '', '小红', '20', '上海');
INSERT INTO `test`.`staff` (`id`, `id_card`, `name`, `age`, `city`) VALUES ('5', '', '小芳', '36', '北京');
INSERT INTO `test`.`staff` (`id`, `id_card`, `name`, `age`, `city`) VALUES ('6', '', '小莉', '19', '深圳');
INSERT INTO `test`.`staff` (`id`, `id_card`, `name`, `age`, `city`) VALUES ('7', '', '小华', '27', '湛江');我们现在有这么一个需求:
查询前10个,来自深圳员工的姓名、年龄、城市,并且按照年龄小到大排序.对应的 SQL 语句就可以这么写:
// 执行SQL语句
select name,age,city from staff where city = '深圳' order by age limit 10;这条语句的逻辑很清楚,但是它的底层执行流程是怎样的呢?
1.解析器接收到sql语句并进行词法分析和语法分析,确保语句的正确性;
2.语义分析器检查表名,列名,关键字等,确保它们存在且拥有正确的权限;
3.查询优化器根据数据库的统计信息,索引和优化规则等,生成多个执行计划;
4.查询优化器评估每个执行计划的成本,并选择最佳的执行计划;
5.执行引擎根据选定的执行计划执行查询;
6.执行引擎通过查询计划中的表名和条件,从数据库中获取满足条件的行;
7.执行引擎对获取的行进行过滤,仅保留城市为"深圳"的行;
8.执行引擎对结果进行排序,按照年龄进行升序排序;
9.执行引擎返回排序后的前10行,包含每行的姓名,年龄和城市;
10.执行引擎将结果返回给应用程序或客户端;
我们先用explain关键字查看一下执行计划;
执行计划的possible_keys这个字段,表示可能使用到的索引;
执行计划的key这个字段,表示使用到索引idx_city;
Extra这个字段的Using index condition 表示索引条件;
Extra这个字段的Using filesort表示用到排序;
我们可以发现;
这条SQL使用到了索引;
并且也用到了排序;
具体它是使用了哪种类型的排序;
那么它是怎么排序的呢?
我们再来查看Extra这个字段;
查看是否存在"Using filesort"或"Using temporary"的标识;
则表示MYSQL使用了磁盘临时文件或辅助排序;
如果计划中没有这些标识;
通常意味着MYSQL使用全字段排序或Rowid排序;
下面我们来说一下全字段排序;
MYSQL会给每个查询线程分配一块小内存,
用于排序的称为sort_buffer;
什么时候把字段放进去排序呢;
其实是通过idx_city索引找到对应数据;
才把数据放进去的;
我们先来回顾一下;
索引是怎么匹配到数据的;
以非聚簇索引为例;
首先通过idx_city索引树 city = '深圳';
叶子节点存储的是主键id;
然后再通过主键id找到磁盘对应的行数据;
加上order by之后;
整体的执行流程就是:
1.MySQL为对应的线程初始化sort_buffer,放入需要查询的name、age、city字段;
2.从索引树idx_city,找到第一个满足city='深圳' 条件的主键id;
3.到主键id索引树拿到id=9的这一行数据,取name、age、city三个字段的值,存到sort_buffer;
4.从索引树idx_city拿到下一个记录的主键id;
5.查找所有city='深圳'的数据;
6.在sort_buffer中,在将数据通过age排序;
7.然后返回前10条给客户端;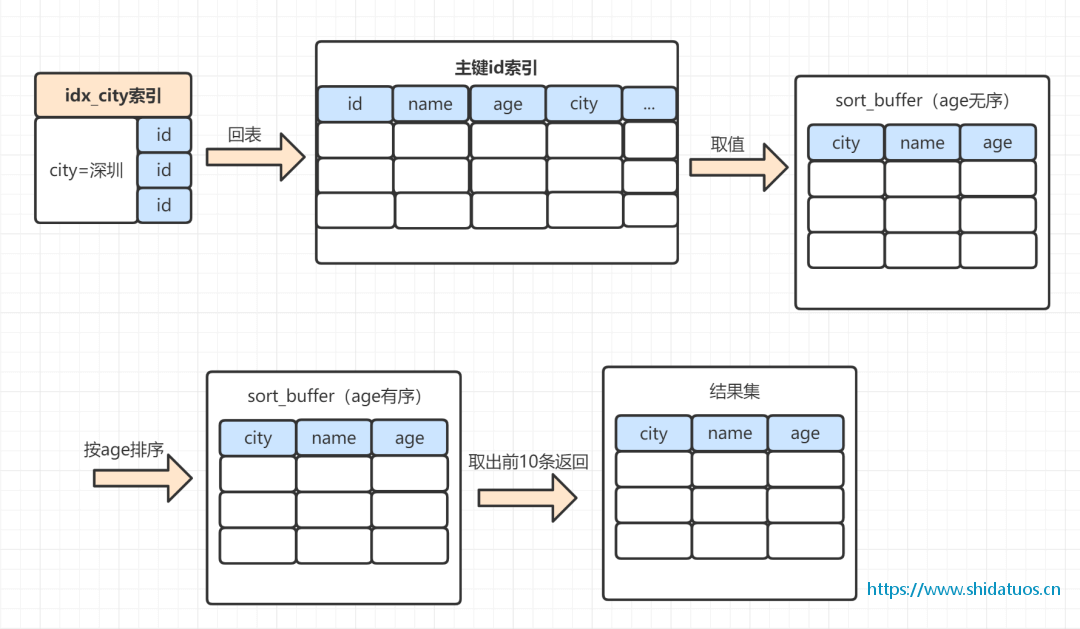
实际上,sort_buffer的大小是由一个参数控制的:sort_buffer_size;
如果要排序的数据小于sort_buffer_size;
排序在sort_buffer内存中完成;
如果要排序的数据大于sort_buffer_size;
则借助磁盘文件来进行排序;
使用了磁盘临时文件,整个排序过程又是怎样的呢?
1.从主键id索引树,拿到需要的数据,并放到sort_buffer内存块中;
当内存sort_buffer快要满时,就对sort_buffer中的数据排序;
排完后,把数据临时放到磁盘一个小文件中;
2.继续回到主键id索引树取数据,继续放到sort_buffer内存中;
排序后,也把这些数据写入磁盘临时小文件中;
3.继续循环,直到取出所有满足条件的数据;
最后把磁盘的临时排好序的小文件,合并成一个有序的大文件;
TPS:借助磁盘临时小文件排序,实际上使用的是归并排序算法;
既然sort_buffer放不下,就需要用到临时磁盘文件;
这会影响排序效率;
那为什么还要把排序不相关的字段(name,city)放到sort_buffer中呢?
只放排序相关的age字段,它不香吗?可以了解下;
本文为史大坨原创文章,转载无需和我联系,但请注明来自史大坨博客https://www.shidatuos.cn
- 上一篇: Amazon 数据采集 API
- 下一篇: Nginx负载均衡配置

- 最新评论
- 总共0条评论




